This feature is only available to customers on the Premier plan or the Pro plan as an add-on. To upgrade, contact your Customer Success Manager or sales@heap.io
Overview
Heap Connect’s Snowflake destination empowers you to access retroactive data in your Snowflake instance with no developer resources needed. This gives you direct access to your Heap data using your Snowflake account via Snowflake Data Sharing, which enables Heap to act as a provider and share data directly with your consumer accounts.
No data is copied or transferred during this sharing, so the shared data does not take up any storage in your Snowflake account. Accordingly, this integration does not contribute to your monthly data storage charges in Snowflake. Your account will only be charged for the compute resources (i.e. virtual warehouses) used to query the shared data.
Requirements
To get started, you need to have the following information about your Snowflake account:
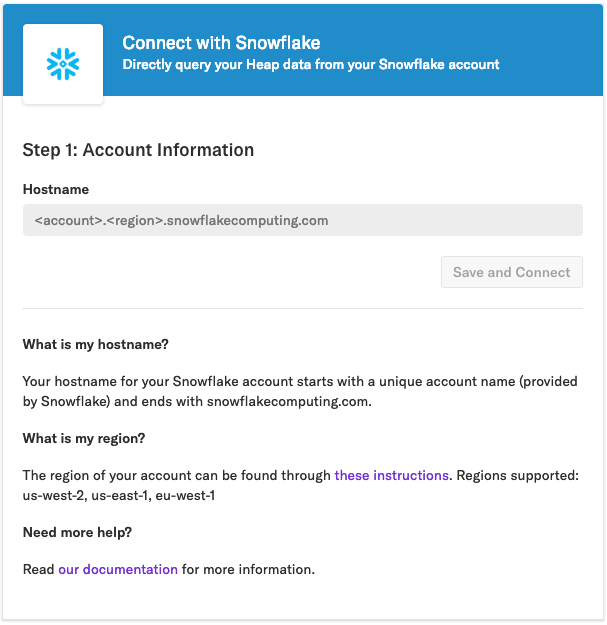
- Your Snowflake account name: Your account name can be found in the URL used to access Snowflake
<account_name>.snowflakecomputing.com - Your account region: We currently support the following regions:
AWS:
- us-west-2 (Oregon): region not included in snowflake URLs for this region only
- us-east-1 (N. Virginia)
- us-east-2 (Ohio)
- eu-west-1 (Ireland)
- eu-central-1 (Frankfurt)
- ap-southeast-2 (Sydney)
- ca-central-1 (Canada Central)
Azure:
- east-us-2 (Virginia)
- west-us-2 (Washington)
- canada-central (Toronto)
- west-europe (Netherlands)
- australia-east (New South Wales)
- north-europe (Ireland)
GCP:
- us-central1 (Iowa)
- europe-west4 (Netherlands)
If you are outside of these regions, please let us know and we will work to add support for you.
To find this information in your Snowflake account, see the Integrate > Connect > Snowflake page in Heap. This page will only be available once Heap Connect has been enabled for you by someone on our end.
Setup
To start setting up Heap Connect for Snowflake, navigate to Integrations > Directory > Snowflake. If the Connect page looks like the image below (meaning it’s your first time using it) you need to talk to someone from our team to be granted access. Use the form on this page to contact our Sales team, or go to Get support in the Heap app.

Once someone on our end has enabled Heap Connect, the warehouses we support will be listed on the left. Select Snowflake, then complete the steps below.
1. Copy-paste the hostname into the corresponding field on the Snowflake page, then click Save and Connect.
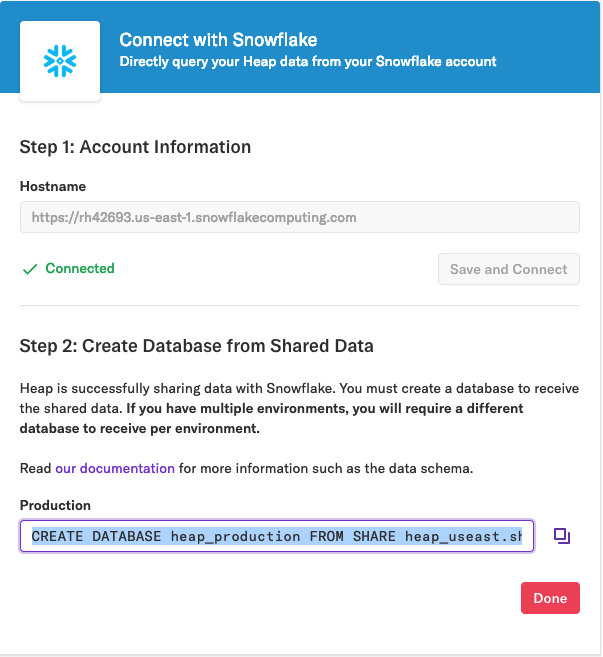
The page will update to confirm that Heap data is successfully being shared with Snowflake. In the next step, we’ve provided a production snippet to create a database for the shared data.
2. Receive the share by copy-pasting the production snippet to create a database from the shared data (share_name provided by Heap).
Data Sharing for Multiple Environments
You will receive a different share for each environment synced in Heap, so you will need to create a different database to receive the data from each environment.
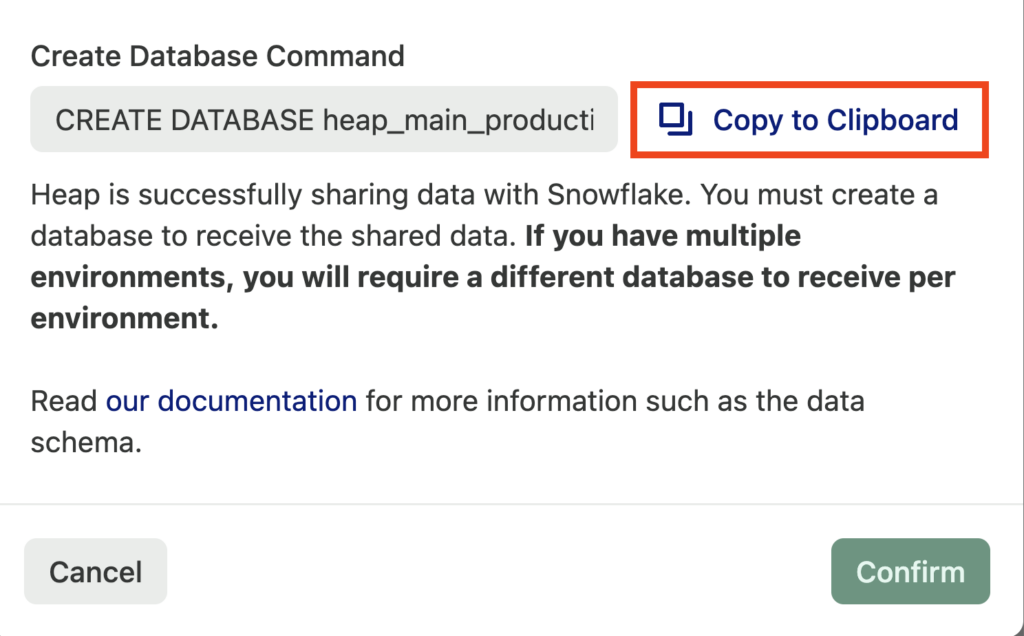
If you need to retrieve the production snippet again, you can do so as follows:
a. From Integrate > Connect > Snowflake, click the configuration (gear) icon.
b. At the bottom of the Snowflake Configuration pop-up, you will see the Create Database Command. Click Copy to Clipboard to retrieve this snippet.
You can learn more about how the data will be structured upon sync by viewing our docs on data syncing.
It may take 24 to 48 hours for us to prepare your account for syncing. This is noted in the ‘sync pending’ state.
3. Query the tables shared with your account. We’ll share the built-in tables (pageviews, users, sessions, all_events) and any event tables you choose to sync. You can explore the tables synced by querying the information_schema or by viewing the sidebar in Snowflake’s UI.
Query example:
// Explore synced tables
SELECT * FROM <database_name>.information_schema.tables;
// Query
SELECT * FROM <database_name>.<schema_name>.<table_name>;Schema
For each environment, Heap will create the following views in Snowflake:
- One
usersview. - One
sessionsview. - One
pageviewsview. - One
all_eventsview. - One view for each event you’ve defined and have set up syncing for in Heap.
These objects have a dynamic schema that auto-updates to reflect any new events or properties you’ve tracked.
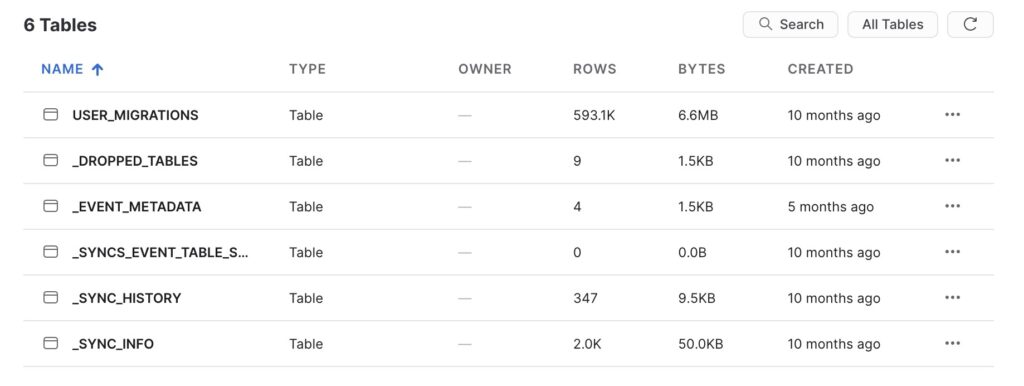
In addition to the objects above, the following metadata tables will be created:
- One
_sync_infotable. - One
_dropped_tablestable. - One
user_migrationstable which lists all instances of merging and migrating users.
For complete schema details, including the columns you should expect to see, see the schema section of our Heap Connect guide.
You can sync Defined Properties to this warehouse.
Time Zones
By default, time zones in Snowflake are set to the local time zone of the region in which your cluster is located. However, you can reconfigure the time zone using their system settings. To do so, review this Snowflake doc on admin account management.
Limitations
For customers moving from our Redshift integration, there are a few things we do not currently support as part of the Snowflake integration. Please provide feedback if these Heap features are important to you.
- Reserved Keywords: Snowflake reserves all ANSI keywords as well as some additional keywords. This means custom Heap properties such as
current_dateorcurrent_userwill not be synced in your Snowflake export. For a full list, see Snowflake’s doc on Reserved & Limited Keywords.
Troubleshooting
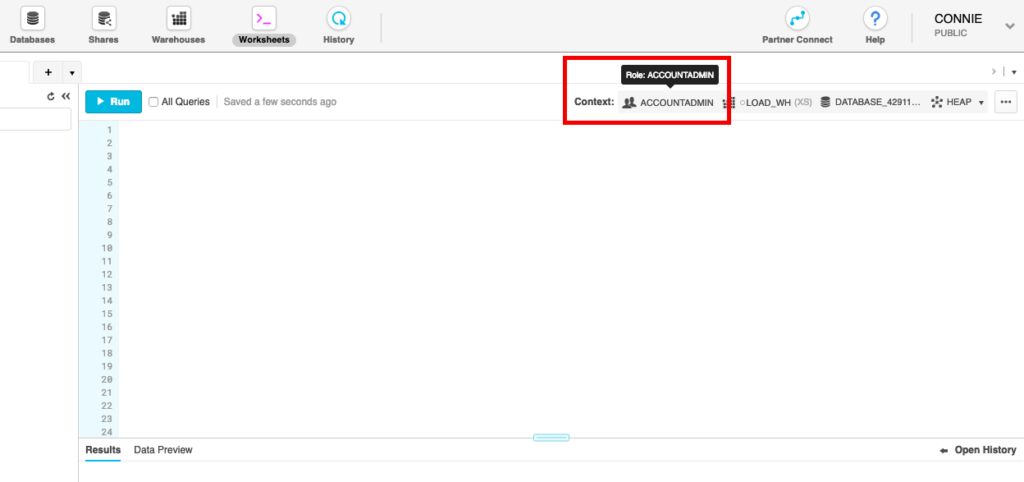
If you are getting the error message SQL access control error: Insufficient privileges to operate on foreign share when trying to create a share using the provided query, make sure you are running the query with an ACCOUNTADMIN role. You can make this selection in Snowflake.
Heap-hosted Snowflake
If you do not currently have Snowflake but want to take advantage of this integration, our team can create a Reader Account for you and share Heap data via this account. This has the advantage of helping you absorb query costs, though it also has the following limitations:
- There is a monthly credit usage limit on the account, and your querying usage will be automatically capped when you reach that limit.
- You cannot import data from other data sources into Snowflake for analysis with the Heap dataset.
- The shared database is read-only, which means it’s not compatible with Looker’s persistent derived tables (PDTs) which require write-access.
Looker Blocks on Snowflake
Because we use Snowflake data sharing, which shares a read-only dataset, there are some modifications that must be made to your Looker Blocks before they can be used on data stored in Snowflake. The modification depends on whether you or Heap is hosting the Snowflake account.
Snowflake hosted by you with Looker Blocks
To modify your database for Looker Blocks, complete the following steps:
- Create a new database in Snowflake with a scratch schema that the Looker user has write-access to – review the instructions in Looker’s Snowflake documentation.
- Create two connections in Looker: one to the Snowflake database receiving the share from Heap, and one to the database from step 1 that contains the scratch schema.
- Create a project in Snowflake using the connection to the database with the scratch schema.
- Install Heap Looker Blocks in this project.
- Change the name of the connection in the model file to be the name of the connection associated with the database where the scratch schema was created.
- In every view file of the Looker Block, modify references to Heap tables by prepending the name of the Snowflake database containing the shared data from Heap.
Example for #6:
view: session_facts {
derived_table: {
sortkeys: ["session_start_time"]
distribution: "session_unique_id"
# update trigger value to desired frequency and time zone
sql_trigger_value: select date(convert_timezone('pst', getdate() - interval '3 hours')) ;;
sql: SELECT
all_events.session_id || '-' || all_events.user_id AS session_unique_id,
user_id,
row_number() over( partition by user_id order by min(all_events.time)) as session_sequence_number,
min(all_events.time) AS session_start_time,
max(all_events.time) AS session_end_time,
COUNT(*) AS "all_events.count"
FROM main_production.all_events AS all_events
GROUP BY 1,2
;;
}
main_production.all_events changes to <shared database name>.heap.all_eventsHeap-hosted Snowflake with Looker Blocks
Heap Looker Blocks are built using Persistent Derived Tables (PDTs), but PDTs require write-access to the schema holding the underlying dataset. A workaround for Heap-hosted Snowflake is to use Looker’s “ephemeral” derived tables instead. You can do this by modifying the view files in the Looker Block and commenting out every reference of sql_trigger_value. This Looker thread provides guidance on how to modify the PDTs.